
Pruna AI, a European startup that has been engaged on compression algorithms for AI fashions, is making its optimization framework open source on Thursday.
Pruna AI has been making a framework that applies a number of effectivity strategies, resembling caching, pruning, quantization and distillation, to a given AI mannequin.
“We additionally standardize saving and loading the compressed fashions, making use of combos of those compression strategies, and likewise evaluating your compressed mannequin after you compress it,” Pruna AI co-fonder and CTO John Rachwan informed TechCrunch.
Specifically, Pruna AI’s framework can consider if there’s important high quality loss after compressing a mannequin and the efficiency positive aspects that you simply get.
“If I have been to make use of a metaphor, we’re much like how Hugging Face standardized transformers and diffusers — tips on how to name them, tips on how to save them, load them, and many others. We’re doing the identical, however for effectivity strategies,” he added.
Huge AI labs have already been utilizing varied compression strategies already. As an example, OpenAI has been counting on distillation to create sooner variations of its flagship fashions.
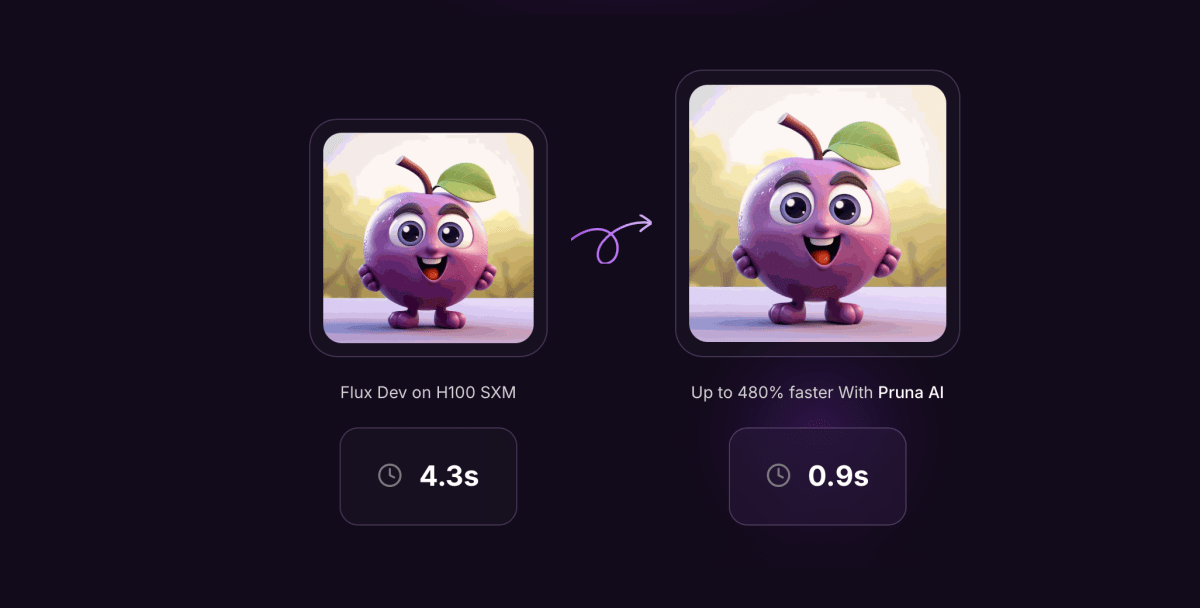
That is seemingly how OpenAI developed GPT-4 Turbo, a sooner model of GPT-4. Equally, the Flux.1-schnell picture era mannequin is a distilled model of the Flux.1 mannequin from Black Forest Labs.
Distillation is a method used to extract data from a big AI mannequin with a “teacher-student” mannequin. Builders ship requests to a trainer mannequin and report the outputs. Solutions are generally in contrast with a dataset to see how correct they’re. These outputs are then used to coach the scholar mannequin, which is skilled to approximate the trainer’s conduct.
“For giant corporations, what they often do is that they construct these items in-house. And what you will discover within the open supply world is often primarily based on single strategies. For instance, let’s say one quantization methodology for LLMs, or one caching methodology for diffusion fashions,” Rachwan mentioned. “However you can’t discover a instrument that aggregates all of them, makes all of them simple to make use of and mix collectively. And that is the large worth that Pruna is bringing proper now.”

Whereas Pruna AI helps any sort of fashions, from giant language fashions to diffusion fashions, speech-to-text fashions and pc imaginative and prescient fashions, the corporate is focusing extra particularly on picture and video era fashions proper now.
A few of Pruna AI’s current customers embrace Scenario and PhotoRoom. Along with the open supply version, Pruna AI has an enterprise providing with superior optimization options together with an optimization agent.
“Essentially the most thrilling characteristic that we’re releasing quickly can be a compression agent,” Rachwan mentioned. “Mainly, you give it your mannequin, you say: ‘I need extra pace however don’t drop my accuracy by greater than 2%.’ After which, the agent will simply do its magic. It should discover the most effective mixture for you, return it for you. You don’t must do something as a developer.”
Pruna AI expenses by the hour for its professional model. “It’s much like how you’d consider a GPU once you hire a GPU on AWS or any cloud service,” Rachwan mentioned.
And in case your mannequin is a crucial a part of your AI infrastructure, you’ll find yourself saving some huge cash on inference with the optimized mannequin. For instance, Pruna AI has made a Llama mannequin eight occasions smaller with out an excessive amount of loss utilizing its compression framework. Pruna AI hopes its clients will take into consideration its compression framework as an funding that pays for itself.
Pruna AI raised a $6.5 million seed funding spherical a number of months in the past. Traders within the startup embrace EQT Ventures, Daphni, Motier Ventures and Kima Ventures.
Trending Merchandise









![Rustic Grey Mason Jar Sconces for Home Decor, Decorative Chic Hanging Wall Decor Mason Jars with LED Strip Lights, 6-Hour Timer, Silk Hydrangea, & Iron Hooks for Home & Kitchen Decorations [Set of 2]](https://m.media-amazon.com/images/I/41DPf4UgGOL._SS300_.jpg)
